In this series of blog posts, I’ve enjoyed shedding some light on how we approach marketing at The Next Web through Web analytics, Search Engine Optimization (SEO), Conversion Rate Optimization (CRO), social media and more. This piece focuses on how and why we’re working with Google Tag Manager and how it helped us so far in improving our Web analytics.
The status of our Google Tag Manager (GTM) account as of mid-February 2016 – and using GTM for over a year – is four containers and in total with 443 Versions, 80 Tags, 85 Triggers, 100 Variables. and the result of us using GTM for just over a year.
What did we learn in the past year about Google Tag Manager? Why did we fall in love with it in the first place and the reason why we moved to it? And finally, what kind of stuff can you find amongst the 80 tags that are in there are just some of the questions we’ll address in this post.
Why we decided to start using Google Tag Manager
Last year, when we just hired our Web analyst, we decided that it was time to not only update our Web analytics integrations (with GA) but also to make sure it was even more flexible. It could have been worse, at the time the marketing team was already able to access all the codebases that we use at The Next Web and make changes to it. But even better, they could actually deploy to it!
As things got more complicated and having the development team using more repositories to store the code for different projects it was getting hard to keep up with changes that needed to be made across the board. On top of that, it’s just not a ton of fun if you have to change the same thing across five plus codebases. That’s why we very quickly decided to move most of the stuff to a tag manager. This made it possible to deploy changes directly across the board and only took one change to implement the GTM container snippet on all the properties.
How do we manage our Google Tag Manager Account?
Let me answer a couple of questions on what the structure looks like in working with GTM:
Why four containers?
Easy answer, we’re running four different sites/projects: thenextweb.com, Index.co, X.Works and TNW Earlybird (our new ticket sales platform).
Who has access?
Five people from the marketing team have access, of which only three have the power to publish the tags. In addition to that the senior developers on all projects have access to GTM in case they need to jump in (this only happened twice in the last year, besides this they tend not to use it).
Do we document our releases and the implementation?
Not always, which is a bad habit, we know.
I did a quick check and found that around 40 percent of our versions don’t have a name. If we give them a name it will usually include a certain change that we made. Just as with normal version control in coding, we tend not to make too many changes to a container before publishing it but rather having publishing more versions on a given day.
For more questions, tweet me @MartijnSch and I’ll include your questions later on in this blogpost!
Moving Google Analytics to Google Tag Manager
In the previous post in this series I wrote about our Web analytics setup through Google Analytics Premium.
While we were in the process of deciding what to do with updating our GA integrations we got advised to move our tracking set ups to Google Tag Manager – it would allow us to implement tracking even faster and also use more features through the dataLayer or on Window Load making our setups better.
That’s why in the first week of January we sat down with the planning that we already had laid out and decided to move all tracking (in one week!).
Looking back it was relatively easy. Our implementation works with both primary and secondary Google Analytics accounts so different teams can track their own projects but also the data for all projects will be gathered in our primary/main property.
Our love relationship with the dataLayer
The dataLayer is currently supporting most of the custom dimensions that we are sending to Google Analytics, which is still our primary use for GTM. It’s currently supporting around 30-35 data elements. From the date and time that this post was published to the author or the number of words.

In general the dataLayer consists of a couple of elements:
- Location: We’d like to know what region and country you’re in so we won’t have to annoy you with irrelevant information.
- Page: Information about the article or page that you’re visiting, example: tags, keywords, author names, published date and time.
- User: Something we’re working on currently, how many articles have you shared on The Next Web and with what kind of networks. Information that might influence later on how you interact with us.
- Ads: In most cases you’ll see a canvas ad in the background, is it commercial or not. What is the name of the canvas, and how many ads do you see and from what sponsor. Data we’d like to know in GTM to send to GA but also in order to see if we can launch pop-ups (for example).
What kind of tags, triggers & variables do we have?
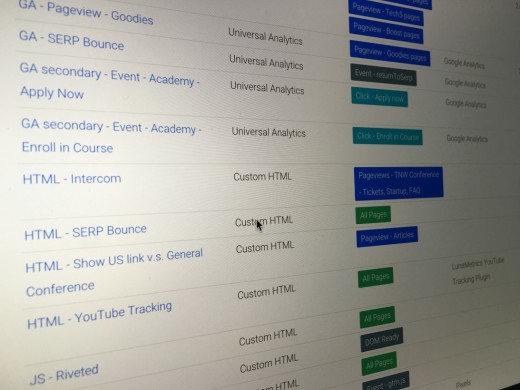
With over 80 tags in total we have quite a lot of stuff implemented. Since it flows and is sent through dataLayer (most of it), it saves some of the use of tags as it makes things a lot more structured.
In general our tags are segmented into a couple of categories: Facebook tracking, Google Analytics tracking, A/B Testing, Twitter tracking and some random JS implementations that power other tracking purposes.
Triggers
Within our triggers we can make sure that we only target specific areas of the site.
The triggers are, as you might know, used to fire the tags. We use the build-in variable for simple straight forward triggers – and some more advanced ones that use dataLayer events and dataLayer variables. For instance, for specific Google Analytics and Facebook events that we track.
Examples: HTTP/HTTPS, Mobile/Desktop, Article/Homepage.
Variables
As our tags send most of the data, the purpose of variables is so that we can clean or set up the data from our dataLayer directly.
Currently we have dozens of dataLayer variables and also a lot of custom ‘Custom JavaScript’ and URL variables (fragments, queries, parameters).
What’s next?
As The Next Web is getting more complex and we’re working on making your experiences very personal, we’ll be storing even more data on the engagement in the dataLayer and making it easily available to use for triggers and variables.
Currently we still send a lot of Google Analytics events directly to GA instead of doing it via GTM. In some codebases to two different GA properties.
We are in the process of moving all GA events to dataLayer events making it easier to maintain event tracking on the website. And we’ll have just one event on a element instead of up to four (2x GA, 1x dataLayer, FB). In GTM we can send it all to the specific trackers with just two tags (GA & FB).
dataLayer:
Our dataLayer is getting more complex and will provide even more information for us to leverage.
AMP:
AMP stands for Accelerated Mobile Pages. It is an open source project by Google with the goal to improve the (reading) experience for users on mobile.
One of the reasons we moved to GTM was that it would be easier and quicker for us to maintain tracking on all the different codebases. Unfortunately AMP is making things difficult for us again, because it doesn’t support GTM.
We have to setup a custom GA implementation to track user behavior on AMP pages. Currently it works with the measurement protocol. AMP released a new version for GA tracking which allows us to track a bit more than the measurement protocol and we will soon update our tracking on the AMP pages.
I’m afraid this will happen often with other platforms as well such as Apple News and Facebook Instant Articles.
In the next blogpost I’ll talk more about how we’re using another Google product: Google Search Console.
I’ll show how we hack our way around it to make sure that we can retrieve more data through 855+ properties (and counting).
If you missed the previous posts in this series, don’t forget to check them out: #1: Heat maps , #2: Deep dive on A/B testing and #3: Learnings from our A/B tests, #4: From Marketing Manager to Recruiter, #5 Running ScreamingFrog in the Cloud and #6 What tools do we use?, #7 We track everything!
This is a #TNWLife article, a look into the lives of those that work at The Next Web.
Get the TNW newsletter
Get the most important tech news in your inbox each week.