
Deep neural networks can perform wonderful feats thanks to their extremely large and complicated web of parameters. But their complexity is also their curse: The inner workings of neural networks are often a mystery — even to their creators. This is a challenge that has been troubling the artificial intelligence community since deep learning started to become popular in the early 2010s.
In tandem with the expansion of deep learning in various domains and applications, there has been a growing interest in developing techniques that try to explain neural networks by examining their results and learned parameters. But these explanations are often erroneous and misleading, and they provide little guidance in fixing possible misconceptions embedded in deep learning models during training.
In a paper published in the peer-reviewed journal Nature Machine Intelligence, scientists at Duke University propose “concept whitening,” a technique that can help steer neural networks toward learning specific concepts without sacrificing performance. Concept whitening bakes interpretability into deep learning models instead of searching for answers in millions of trained parameters. The technique, which can be applied to convolutional neural networks, shows promising results and can have great implications for how we perceive future research in artificial intelligence.
Features and latent space in deep learning models
Given enough quality training examples, a deep learning model with the right architecture should be able to discriminate between different types of input. For instance, in the case of computer vision tasks, a trained neural network will be able to transform the pixel values of an image into their corresponding class. (Since concept whitening is meant for image recognition, we’ll stick to this subset of machine learning tasks. But many of the topics discussed here apply to deep learning in general.)
During training, each layer of a deep learning model encodes the features of the training images into a set of numerical values and stores them in its parameters. This is called the latent space of the AI model. In general, the lower layers of a multilayered convolutional neural network will learn basic features such as corners and edges. The higher layers of the neural network will learn to detect more complex features such as faces, objects, full scenes, etc.


The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
Ideally, a neural network’s latent space would represent concepts that are relevant to the classes of images it is meant to detect. But we don’t know that for sure, and deep learning models are prone to learning the most discriminative features, even if they’re the wrong ones.
For instance, the following data set contains images of cats that happen to have a logo in the lower right corner. A human would easily dismiss the logo as irrelevant to the task. But a deep learning model might find it to be the easiest and most efficient way to tell the difference between cats and other animals. Likewise, if all the images of sheep in your training set contain large swaths of green pastures, your neural network might learn to detect green farmlands instead of sheep.
[Read: ]

So, aside from how well a deep learning model performs on training and test data sets, it is important to know which concepts and features it has learned to detect. This is where classic explanation techniques come into play.
Post hoc explanations of neural networks
Many deep learning explanation techniques are post hoc, which means they try to make sense of a trained neural network by examining its output and its parameter values. For instance, one popular technique to determine what a neural network sees in an image is to mask different parts of an input image and observes how these changes affect the output of the deep learning model. This technique helps create heatmaps that highlight the features of the image that are more relevant to the neural network.

Other post hoc techniques involve turning different artificial neurons on and off and examining how these changes affect the output of the AI model. These methods can help find hints about relations between features and the latent space.
While these methods are helpful, they still treat deep learning models like black boxes and don’t paint a definite picture of the workings of neural networks.
‘Explanation’ methods are often summary statistics of performance (e.g., local approximations, general trends on node activation) rather than actual explanations of the model’s calculations,” the authors of the concept whitening paper write.
For instance, the problem with saliency maps is that they often miss showing the wrong things that the neural network might have learned. And interpreting the role of single neurons becomes very difficult when the features of a neural network are scattered across the latent space.

“Deep neural networks (NNs) are very powerful in image recognition but what is learned in the hidden layers of NNs is unknown due to its complexity. Lack of interpretability makes NNs untrustworthy and hard to troubleshoot,” Zhi Chen, Ph.D. student in computer science at Duke University and lead author of the concept whitening paper, told TechTalks. “Many previous works attempt to explain post hoc what has been learned by the models, such as what concept is learned by each neuron. But these methods heavily rely on the assumption that these concepts are actually learned by the network (which they are not) and concentrated on one neuron (again, this is not true in practice).”
Cynthia Rudin, professor of computer science at Duke University and co-author of the concept whitening paper, had previously warned about the dangers of trusting black-box explanation techniques and had shown how such methods could provide erroneous interpretations of neural networks. In a previous paper, also published in Nature Machine Intelligence, Rudin had encouraged the use and development of AI models that are inherently interpretable. Rudin, who is also Zhi’s Ph.D. advisor, directs Duke University’s Prediction Analysis Lab, which focuses on interpretable machine learning.
The goal of concept whitening is to develop neural networks whose latent space is aligned with the concepts that are relevant to the task it has been trained for. This approach will make the deep learning model interpretable and makes it much easier to figure out the relations between the features of an input image and the output of the neural network.
“Our work directly alters the neural network to disentangle the latent space so that the axes are aligned with known concepts,” Rudin told TechTalks.
Baking concepts into neural networks

Deep learning models are usually trained on a single data set of annotated examples. Concept whitening introduces a second data set that contains examples of the concepts. These concepts are related to the AI model’s main task. For instance, if your deep learning model detects bedrooms, relevant concepts would include bed, fridge, lamp, window, door, etc.
“The representative samples can be chosen manually, as they might constitute our definition of interpretability,” Chen says. “Machine learning practitioners may collect these samples by any means to create their own concept datasets suitable for their application. For example, one can ask doctors to select representative X-ray images to define medical concepts.”
With concept whitening, the deep learning model goes through two parallel training cycles. While the neural network tunes its overall parameters to represent the classes in the main task, concept whitening adjusts specific neurons in each layer to align them with the classes included in the concept data set.
The result is a disentangled latent space, where concepts are neatly separated in each layer and the activation of neurons corresponds with their respective concepts. “Such disentanglement can provide us with a much clearer understanding of how the network gradually learns concepts over layers,” Chen says.
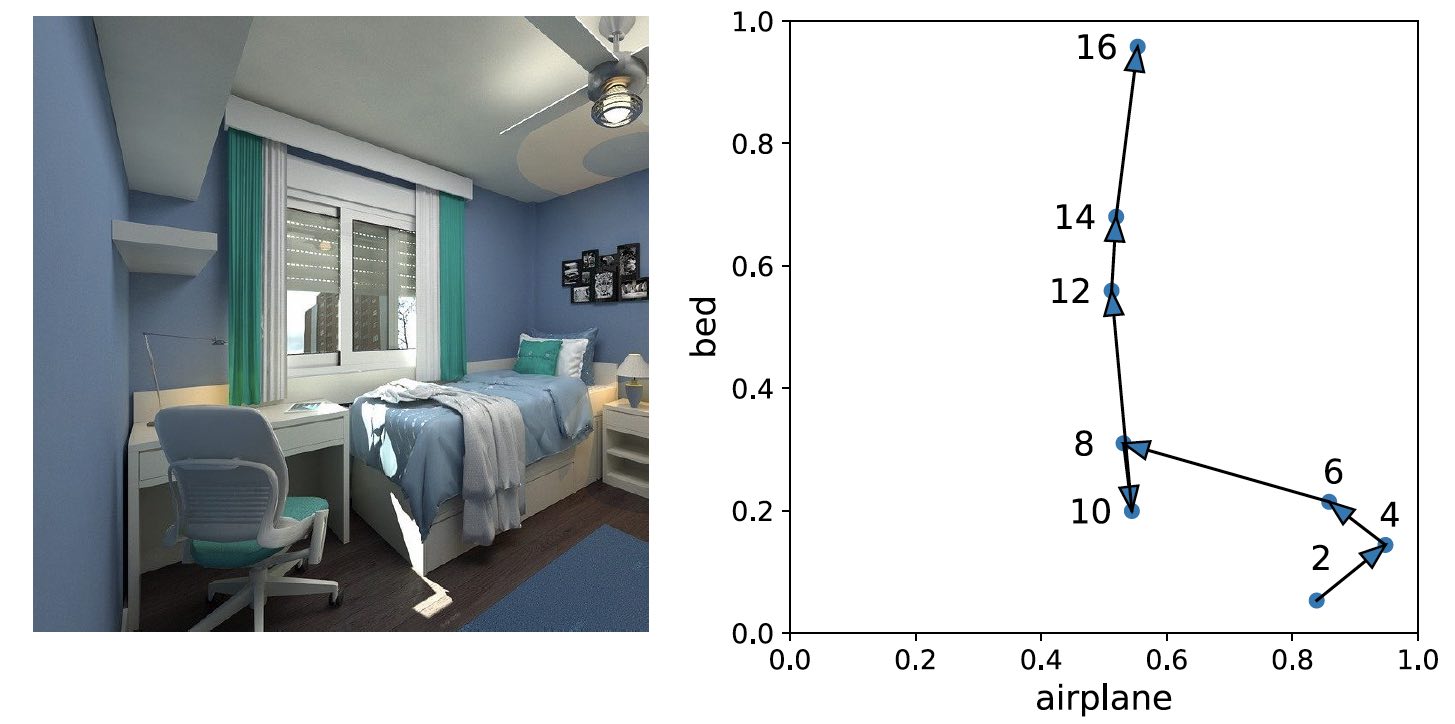
To evaluate the effectiveness of the technique, the researchers ran a series of validation images through a deep learning model with concept whitening modules inserted at different layers. They then sorted the images based on which concept neurons they had activated at each layer. In the lower layers, the concept whitening module captures low-level characteristics such as colors and textures. For instance, the lower layers of the network can learn that blue images with white objects are closely associated with the concept “airplane” and images with warm colors are more likely to contain the concept “bed.” In the higher layers, the network learns to classify the objects that represent the concept.

One of the benefits of concept disentanglement and alignments is that the neural network becomes less prone to making obvious mistakes. As an image runs through the network, the concept neurons in the higher layers correct the errors that might have happened in the lower layers. For instance, in the image below, the lower layers of the neural network mistakenly associated the image with the concept “airplane” because of the dense presence of blue and white pixels. But as the image moves through the higher layers, the concept neurons help steer the results in the right direction (visualized in the graph to the right).
Previous efforts in the field involved creating classifiers that tried to infer concepts from the values in a neural network’s latent space. But, according to Chen, without a disentangled latent space, the concepts learned by these methods are not pure because the prediction scores of the concept neurons can be correlated. “Some people have tried to disentangle neural networks in supervised ways before, but not in a way that actually worked to disentangle the space. CW, on the other hand, truly disentangles these concepts by decorrelating the axes using a whitening transformation,” he says.
Applying concept whitening to deep learning applications
Concept whitening is a module that can be inserted into convolutional neural networks instead of the batch normalization module. Introduced in 2015, batch normalization is a popular technique that adjusts the distribution of the data used to train the neural network to speed up training and avoid artifacts such as overfitting. Most popular convolutional neural networks use batch normalization in various layers.
In addition to the functions of batch normalization, concept whitening also aligns the data along several axes that represent relevant concepts.
The benefit of concept whitening’s architecture is that it can be easily integrated into many existing deep learning models. During their research, the scientists modified several popular pre-trained deep learning models by replacing batch norm modules with concept whitening, and they achieved the desired results with just one epoch of training. (One epoch is a round of training on the full training set. Deep learning modules usually undergo many epochs when trained from scratch.)
“CW could be applied to domains like medical imaging where interpretability is very important,” Rudin says.
In their experiments, the researchers applied concept whitening to a deep learning model for skin lesion diagnosis. “Concept importance scores measured on the CW latent space can provide practical insights on which concepts are potentially more important in skin lesion diagnosis,” they write in their paper.
“For future direction, instead of relying on predefined concepts, we plan to discover the concepts from the dataset, especially useful undefined concepts that are yet to be discovered,” Chen says. “We can then explicitly represent these discovered concepts in the latent space of neural networks, in a disentangled way, for better interpretability.”
Another direction of research is organizing concepts in hierarchies and disentangling clusters of concepts rather than individual concepts.
Implications for deep learning research

With deep learning models becoming larger and more complicated every year, there are different discussions on how to deal with the transparency problem of neural networks.
One of the main arguments is to observe how AI models behave instead of trying to look inside the black box. This is the same way we study the brains of animals and humans, conducting experiments and recording activations. Any attempt to impose interpretability design constraints on neural networks will result in inferior models, proponents of this theory argue. If the brain evolved through billions of iterations without intelligent top-down design, then neural networks should also reach their peak performance through a pure evolutionary path.
Concept whitening refutes this theory and proves that we can impose top-down design constraints on neural networks without causing any performance penalties. Interestingly, experiments show that deep learning models concept whitening modules provide interpretability without a significant drop in accuracy on the main task.
“CW and many other works from our lab (and many other labs) clearly show the possibility of building an interpretable model without hurting the performance,” Rudin says. “We hope our work can shift people’s assumption that a black box is necessary for good performance, and can attract more people to build interpretable models in their fields.”
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.