
Imagine. You spend your formative high school years with your nose in a weighty textbook, at the same time avoiding parties and dating. Then, clutching a 4.0 GPA, you head to a top-tier university to study Computer Science. Four years and a mountain of student debt later, you start your Master’s Degree. The goal is to land a job at a top-tier tech firm, like Facebook, Apple, or Amazon.
And you do. Your job is now to count things.
It sounds like a joke, but that’s pretty much what happened to one of my friends. It turns out that counting is fundamental to how most technology companies work, and it’s also a really fearsome technological problem. Facebook has to count advertising impressions and clicks, while Amazon is responsible for keeping detailed records of sales. And this is a problem that gets significantly harder when you’re operating at global scale.
There are countless algorithms that tackle this problem. Many hashing algorithms center around an approach that sees items split randomly into “buckets” and then sorted. But now, MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), has found an easier way that applies machine learning to the problem.
This approach, called LearnedSketch, is particularly good at finding trends in large datasets, allowing it to find “edge” examples (my clumsy terminology, not theirs). An example would be if you’re looking at a stream of IP addresses, and are trying to identify large sources of traffic.
According to MIT CSAIL, LearnedSketch tries to predict if a specific object will appear in a data stream using machine learning. If it does, the item is moved into a bucket of “heavy hitters,” which are separated for analysis. As the name implies, these are items that most frequently appear within a stream. Otherwise, it’s separated and analyzed using traditional hashing algorithms.
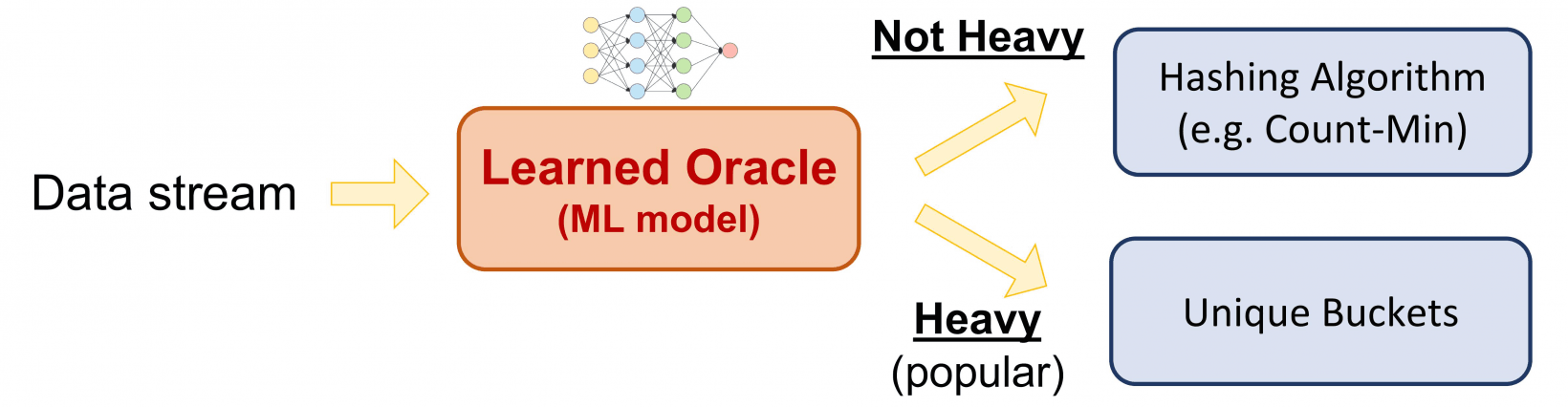
MIT professor Piotr Indyk describes this hybrid approach as a “triage” system where the more challenging problems are tackled before smaller ones. “By learning the properties of heavy hitters as they come in, we can do frequency-estimation much more efficiently and with much less error,” he said.
And it works. According to MIT CSAIL, LearnedSketch has upwards of 57 percent less error when used at, for example, estimating the amount of traffic on a network. For simpler tasks, like estimating the number of queries for a specific search term, the algorithm has 71 percent fewer errors. These are existing problems that have dogged computer scientists for years.
MIT reckons developers can apply LearnedSketch to other problems, ranging to security (identifying DDoS attacks before they cripple a website) to e-commerce (identifying customer interest, allowing sites to devote more resources to a particular niche). If you’re curious, you can check out the paper here.
TNW Conference 2019 is coming! Check out our glorious new location, an inspiring line-up of speakers and activities, and how to be a part of this annual tech extravaganza by clicking here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.