
Facebook today revealed details about Autoscale, a system for power-efficient load balancing that has been rolled out to production clusters in its data centers. The company says it has “demonstrated significant energy savings.”
For those who don’t know, load balancing refers to distributing workloads across multiple computing resources, in this case servers. The goal is to optimize resource use, which can mean different things depending on the task at hand.
In short, Facebook has switched its load-balancing policy from a modified round-robin algorithm (every server receives roughly the same number of page requests and utilizes roughly the same amount of CPU) to concentrate workload to a server until it has at least a medium-level workload. This is because typical Web server at Facebook consume about 60 watts of power when idle (0 requests-per-second, or RPS), 130 watts when at low-level CPU utilization (small RPS), and 150 watts at medium-level CPU utilization.
If the overall workload is low during a given time, the load balancer will use only a subset of servers, leaving the rest at idle or using them for batch-processing workloads. Autoscale can also dynamically adjust the active pool size such that each active server will get at least medium-level CPU utilization regardless of the overall workload level.

The 💜 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
This comes down to a feedback loop control problem:

The control loop starts with collecting utilization information (CPU, request queue, and so on) from all active servers. The Autoscale controller then decides on the optimal active pool size and passes the decision to the load balancers, which distribute the workload evenly.
The decision logic has to both maximize the energy-saving as well as ensure not to over-concentrate traffic in a way that affects site performance. Here is how Facebook tackles this:
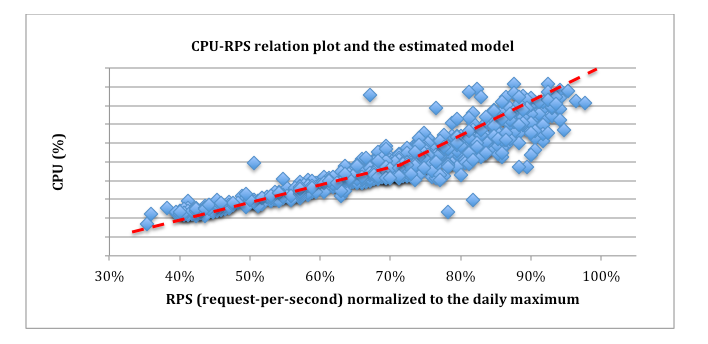
For this to work, we employ the classic control theory and PI controller to get the optimal control effect of fast reaction time, small overshoots, etc. To apply the control theory, we need to first model the relationship of key factors such as CPU utilization and request-per-second (RPS). To do this, we conduct experiments to understand how they correlate and then estimate the model based on experimental data.
For example, Figure 2 shows the experimental results of the relationship between CPU and RPS for one type of web server at Facebook. In the figure, the blue dots are the raw data points while the red dashed line is the estimated model (piece-wise linear). With the models obtained, the controller is then designed using the classic stability analysis to pick the best control parameters.
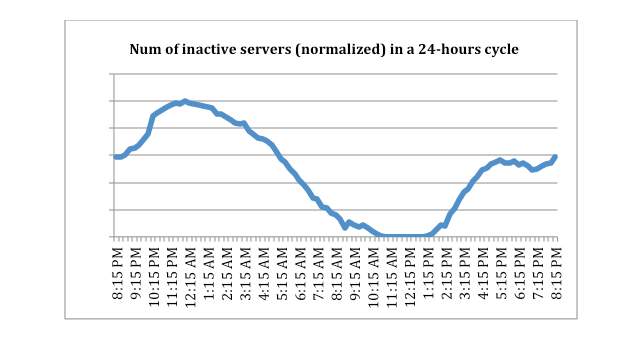
Facebook says that currently, it either leaves “inactive” servers running idle to save energy or repurposes the inactive capacity for batch-processing tasks. The company says both have improved its overall energy efficiency.
Here are the results from one production Web cluster at Facebook, showing the number of servers put into inactive mode by Autoscale:
More importantly, here is the total power consumption for one production web cluster when putting inactive servers into power saving mode:
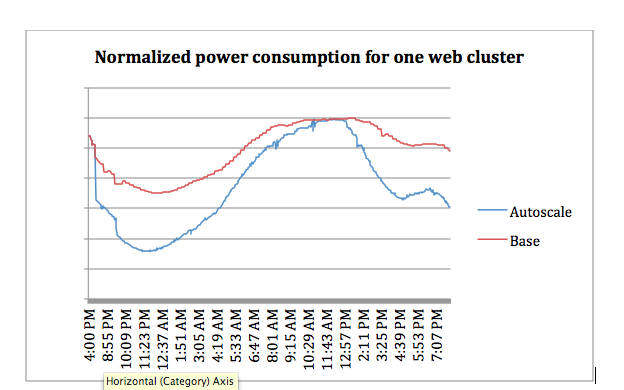
The red line shows the best Facebook could do without Autoscale. In this cluster, Autoscale led to a 27 percent power savings around midnight (power saving was 0 percent around peak hours). Facebook says the average power saving for different Web clusters over a 24-hour cycle was about 10 to 15 percent.
Facebook already does a lot in regards to improving energy efficiency and reducing environmental via its hardware and data center design through the Open Compute Project. Yet the fact improvements can also be achieved with software alone should help motivate other companies to consider doing the same without having to change anything in their physical infrastructure.
Top Image Credit: Brendan Smialowski / Getty Images
Get the TNW newsletter
Get the most important tech news in your inbox each week.