As much as we love to fawn over artificial intelligence (AI), it’s still not great at recognizing and parsing natural language. That’s why Google is open sourcing its new language parsing model for English, which it calls ‘Parsey McParseface.’
Before you even ask, the name doesn’t mean anything. When Google was trying to figure out what to call its language parsing technology, someone suggested Parsey McParseface; it’s a bit like Apple’s Liam, which has no clever backstory either. The overall AI model model is called SyntaxNet (please make your SkyNet jokes now); ‘ol Parsey is just for English.
Note: Sore readers have (often rudely) pointed out the name may be in reference to Boaty McBoatface. Truth told, I don’t really care why Google named it what they did. The underlying tech is far more important and interesting than a silly name. Please continue Ready McReading the article now.
Combining machine learning and search techniques, Parsey McParseface is 94 percent accurate, according to Google. It also leans on SyntaxNet’s neural-network framework for analyzing the linguistic structure of a sentence or statement, which parses the functional role of each word in a sentence.
If you’re confused, here’s the short version: Parsey and SyntaxNet are basically like five year old humans who are learning the nuances of language.
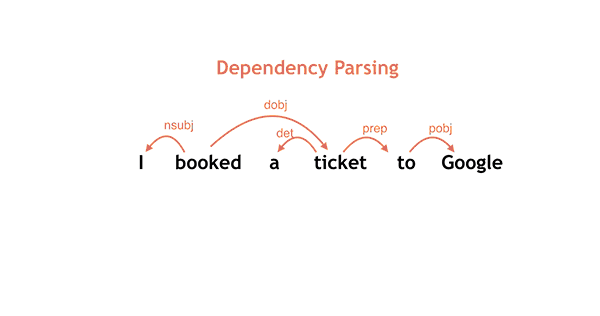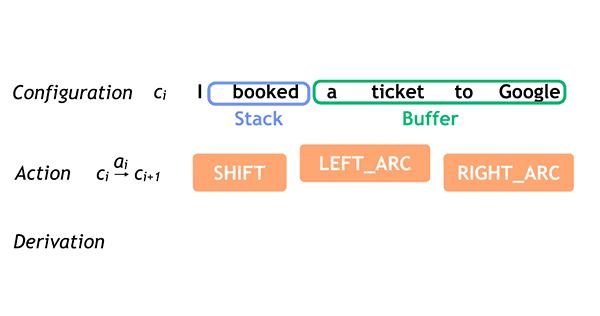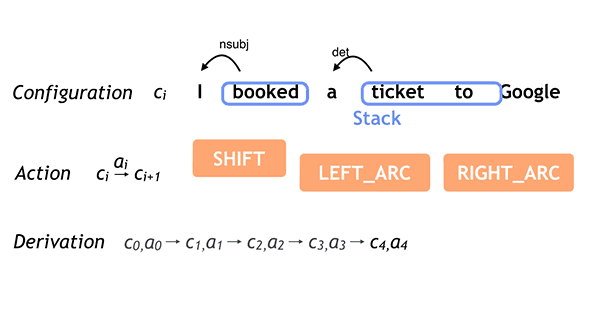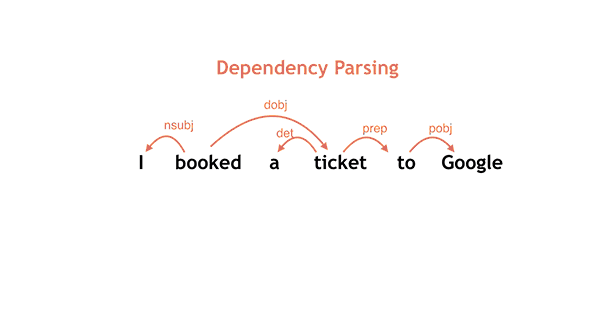
In Google’s simple example above, ‘saw’ is the root word (verb) for the sentence, while ‘Alice’ and ‘Bob’ are subjects (nouns). Parsey’s scope can get a bit broader, too.
And if you’re wondering why Parsey McParseface is even necessary, here’s Google’s explanation:
One of the main problems that makes parsing so challenging is that human languages show remarkable levels of ambiguity. It is not uncommon for moderate length sentences – say 20 or 30 words in length – to have hundreds, thousands, or even tens of thousands of possible syntactic structures. A natural language parser must somehow search through all of these alternatives, and find the most plausible structure given the context.
Parsey McParseface and SyntaxNet aren’t a solution; Google considers them a first step toward better AI language parsing, which is a persistent hurdle.
Besides, a more natural conversation could make Chirp really awesome someday.
Get the TNW newsletter
Get the most important tech news in your inbox each week.