
They promised us the robots wouldn’t attack…
In what seems like dialogue lifted straight from the pages of a post-apocalyptic science fiction novel, researchers from the University of Massachusetts Amherst and Stanford claim they’ve developed an algorithmic framework that guarantees AI won’t misbehave.
The framework uses ‘Seldonian’ algorithms, named for the protagonist of Isaac Asimov’s “Foundation” series, a continuation of the fictional universe where the author’s “Laws of Robotics” first appeared.
According to the team’s research, the Seldonian architecture allows developers to define their own operating conditions in order to prevent systems from crossing certain thresholds while training or optimizing. In essence, this should allow developers to keep AI systems from harming or discriminating against humans.

The <3 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
Deep learning systems power everything from facial recognition to stock market predictions. In most cases, such as image recognition, it doesn’t really matter how the machines come to their conclusions as long as they’re correct. If an AI can identify cats with 90 percent accuracy, we’d probably consider that successful. But when it comes matters of more importance, such as algorithms that predict recidivism or AI that automates medication dosing, there’s little to no margin for error.
To this end, the researchers used their Seldonian algorithm framework to create an AI system that monitors and distributes insulin in diabetics and another that predicts students’ GPAs. In the former, the researchers instituted the Seldonian framework to guarantee that the system wouldn’t send patients into a crash while learning to optimize dosage. And in the latter, they sought to prevent gender bias.
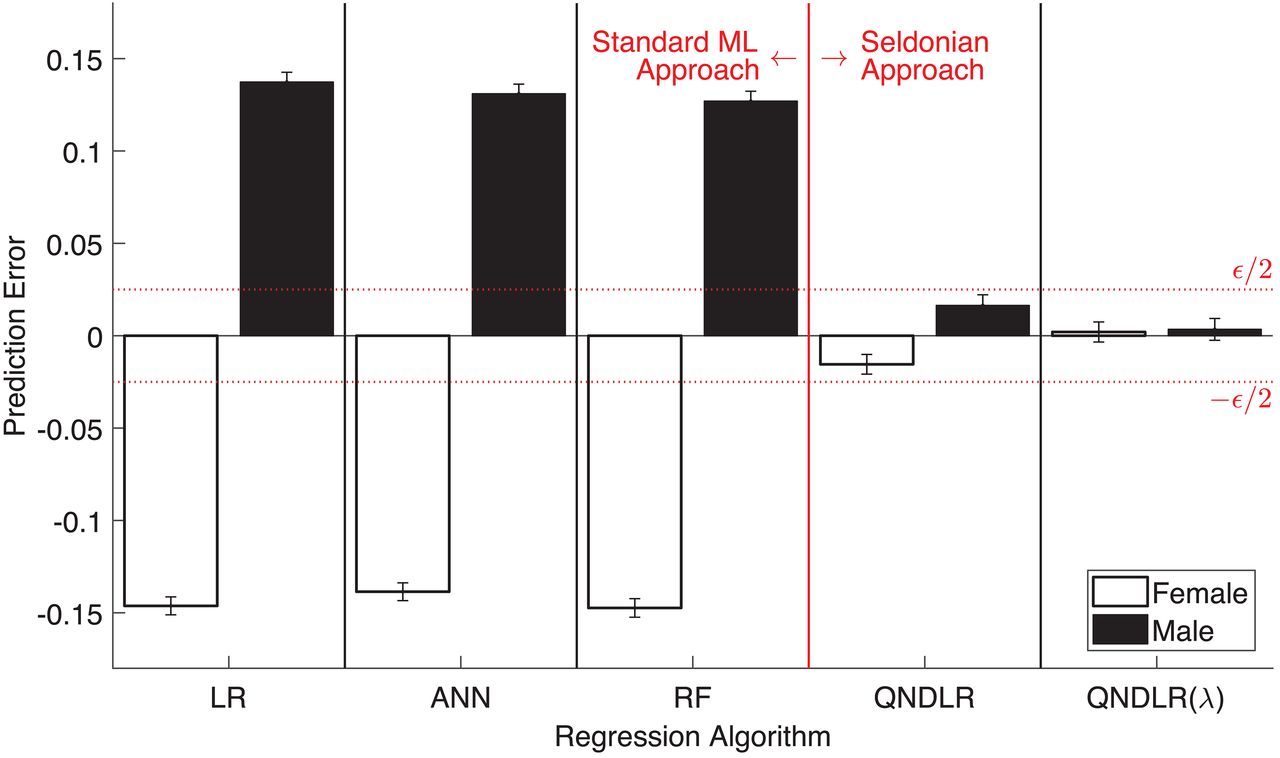
Both experiments proved effective and, according to the researchers, successfully demonstrated that Seldonian algorithms can inhibit unwanted behavior.
The current AI development paradigm places the burden of combating bias on the end user. For example, Amazon’s Rekognition software, a facial recognition technology used by law enforcement, works best if the accuracy threshold is turned down but it demonstrates clear racial bias at such levels. Cops using the software have to choose whether they want to use the technology ethically or successfully.
The Seldonian framework should take this burden off the end-user and place it where it belongs: on the developers. By including the proper mitigation algorithms – something that tells the machine, for example, “find faces without racial bias” it would eliminate the potential for harmful bias while still allowing the software to work.
This is done mathematically. The researchers demonstrate several simple algorithms that express unwanted behavior in terms the machine can understand. So, rather than tell a machine “don’t let gender bias affect your GPA predictions,” the Seldonian algorithms express the problem more like ‘accurately predict everyone’s GPA, but don’t let the differences between predicted GPA and actual GPA exceed a certain threshold when gender is taken into account.’
The researchers hope that with further development the framework can do more than just overhaul current AI technology, according to the team’s paper:
Algorithms designed using our framework are not just a replacement for ML algorithms in existing applications; it is our hope that they will pave the way for new applications for which the use of ML was previously deemed to be too risky.
The implications for near-term technology such as driverless cars and autonomous robot workers are huge, this is essentially the groundwork for Asimov’s “Laws of Robotics.” If developers can guarantee that learning machines won’t pick up dangerous behaviors or suddenly decide to optimize their programming in ways that involve hurting or imprisoning humans, we could be on the verge of a golden age of AI.
Get the TNW newsletter
Get the most important tech news in your inbox each week.