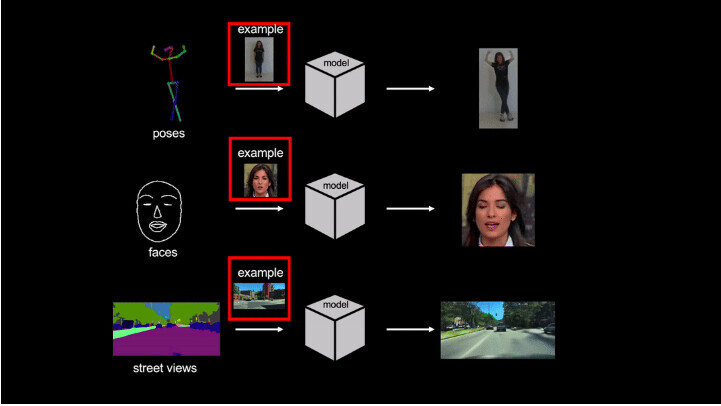
Nvidia’s research team has just developed a new AI that can use an existing video and just one image to make the person in the image imitate moves from the video.
Technically, the method known as video-to-video synthesis takes an input video like a segmentation mask or human poses to turn it into a photorealistic video using an image.
The research team said there are two major problems with the current set of AI models trying to achieve the same: First, these models need a trove of target images to turn them into a video. And second, the capability of these models to generalize the output is limited.
To overcome these obstacles, researchers trained a new model that learns to generate videos of previously unseen humans or scenes – images that weren’t present in the training dataset – using just a few images of them. The team then tested this over various scenarios such as dance moves and talking heads. You can check out the AI in action in the video below:
The model can also be used on paintings or streets to create live avatars or digitally mastered street scenes. This can be really handy for creating movies and games.
As folks discussing in this Hacker News thread pointed out, the AI is not quite perfect, and it’s hard to tell if it’s getting all the details right in these low-resolution videos. However, it’s useful to research towards producing synthesized videos.
You can read more about the research through this paper. You can also look at the code and make your own modifications by checking out the code here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.