
This article is part of our reviews of AI research papers, a series of posts that explore the latest findings in artificial intelligence.
With their millions and billions of numerical parameters, deep learning models can do many things: detect objects in photos, recognize speech, generate text—and hide malware. Neural networks can embed malicious payloads without triggering anti-malware software, researchers at the University of California, San Diego, and the University of Illinois have found.
Their malware-hiding technique, EvilModel, sheds light on the security concerns of deep learning, which has become a hot topic of discussion in machine learning and cybersecurity conferences. As deep learning becomes ingrained in applications we use every day, the security community needs to think about new ways to protect users against their emerging threats.
Hiding malware in deep learning models
Every deep learning model is composed of multiple layers of artificial neurons. Based on the type of layer, each neuron has connections to all or some of the neurons in its previous and next layer. The strength of these connections is defined by numerical parameters that are during training, as the DL model learns the task it has been designed for. Large neural networks can comprise hundreds of millions or even billions of parameters.
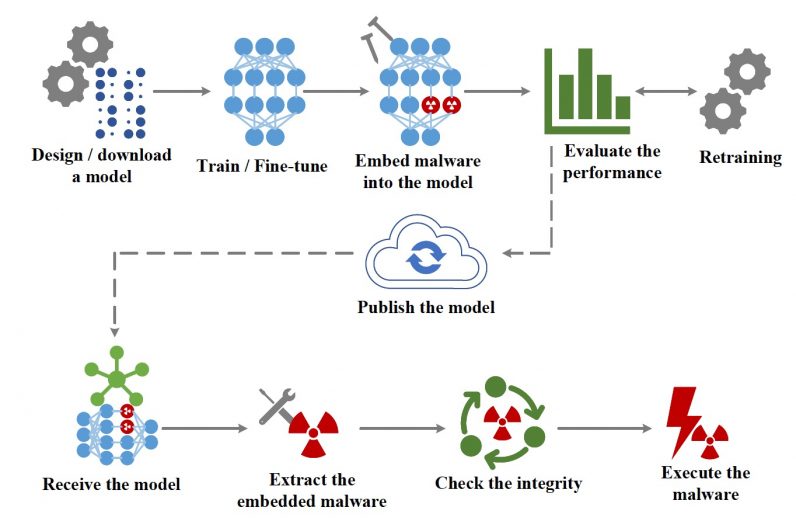
The main idea behind EvilModel is to embed malware into the parameters of a neural network in a way that make it invisible to malware scanners. This is a form of steganography, the practice of concealing one piece of information in another.
At the same time, the infected deep learning model must perform its main task (e.g., classifying images) as well or almost as well as a clean model to avoid causing suspicion or making it useless to its victims.
Finally, the attacker must have a mechanism to deliver the infected model to the target devices and extract the malware from the parameters of the neural network.
Changing parameter values
Most deep learning models use 32-bit (4 bytes) floating-point numbers to store parameter values. According to the researchers’ experiments, an attacker can store up to 3 bytes of malware in each parameter without affecting its value significantly.

When infecting the deep learning model, the attacker breaks the malware into 3-byte pieces and embeds the data into its parameters. To deliver the malware to the target, the attacker can publish the infected neural network on one of several online locations that host deep learning models such as GitHub or TorchHub. Alternatively, the attacker can stage a more complicated form of supply chain attack, where the infected model is delivered through automatic updates to software installed on the target device.
Once the infected model is delivered to the victim, a piece of software extracts the payload and executes it.
Hiding malware in convolutional neural networks
To verify the feasibility of EvilModel, the researchers tested it on several convolutional neural networks (CNN). Several reasons make CNNs an interesting study. First, they are fairly large, usually containing dozens of layers and millions of parameters. Second, they contain a diverse architecture and encompass different types of layers (fully connected, convolutional) and different generalization techniques (batch normalization, dropout layers, pooling layers, etc.), which makes it possible to evaluate the effects of malware-embedding in different settings. Third, CNNs are widely used in computer vision applications, which could make them a prime target for malicious actors. And finally, there are numerous pretrained CNNs that are ready to be integrated into applications without any change, and many developers use pretrained CNNs in their applications without necessarily knowing how deep learning works under the hood.
The researchers first tried embedding malware in AlexNet, a popular CNN which helped renew interest in deep learning in 2012. AlexNet is 178 megabytes and has five convolutional layers and three dense (or fully connected) layers.
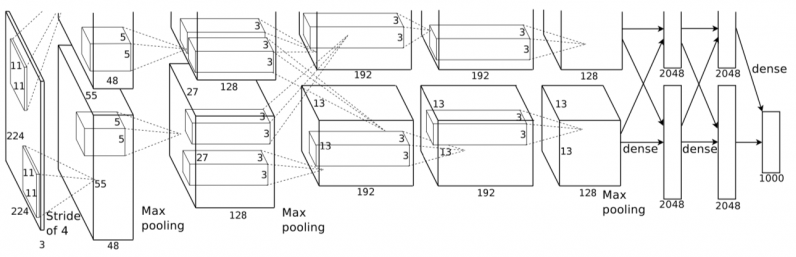
When AlexNet was trained with batch normalization, a technique that standardizes training examples in groups before running them through the deep learning model, the researchers were able to embed 26.8 megabytes of malware in the model while keeping its accuracy within 1-percent of the clean version. If they increased the volume of malware data, the accuracy would start to drop significantly.
They next tried to retrain the model after infecting it. By freezing the infected neurons, they prevented them from being modified during the extra training cycles. With batch normalization and retraining, the researchers could increase the volume of malware data to 36.9 megabytes while maintaining the model’s accuracy above 90 percent.
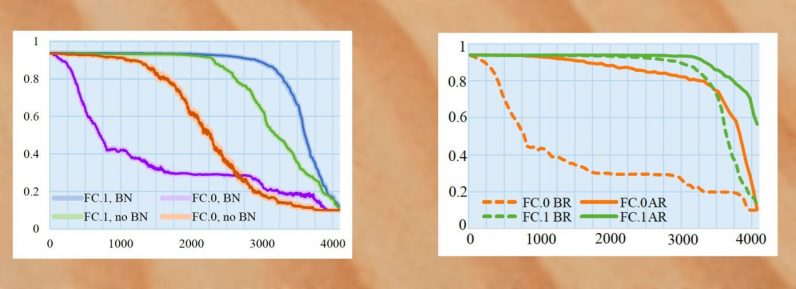
The models were infected with eight samples from the InQuest database, all of which were recognized as malware by the online VirusTotal scanner. Once the samples were embedded in the neural networks, the entire model was uploaded in VirusTotal but was marked as safe, which proves that the malware was well hidden.
The researchers tested the technique on several other CNN architectures, including VGG, Resnet, Inception, and Mobilenet. They obtained similar results, which shows that malware-embedding is a universal threat to large neural networks.
Securing machine learning pipelines
As malware scanners can’t detect malicious payloads embedded in deep learning models, the only countermeasure against EvilModel is to destroy the malware.
The payload only maintains its integrity if its bytes remain intact. Therefore, if the recipient of an EvilModel retrains the neural network without freezing the infected layer, its parameter values will change and the malware data will be destroyed. Even a single epoch of training is probably enough to destroy any malware embedded in the DL model.
However, most developers use pretrained models as they are, unless they want to fine-tune them for another application. And some forms of finetuning freeze most existing layers in the network, which might include the infected layers.
This means that alongside adversarial attacks, data-poisoning, membership inference, and other known security issues, malware-infected neural networks are a real threat to the future of deep learning.
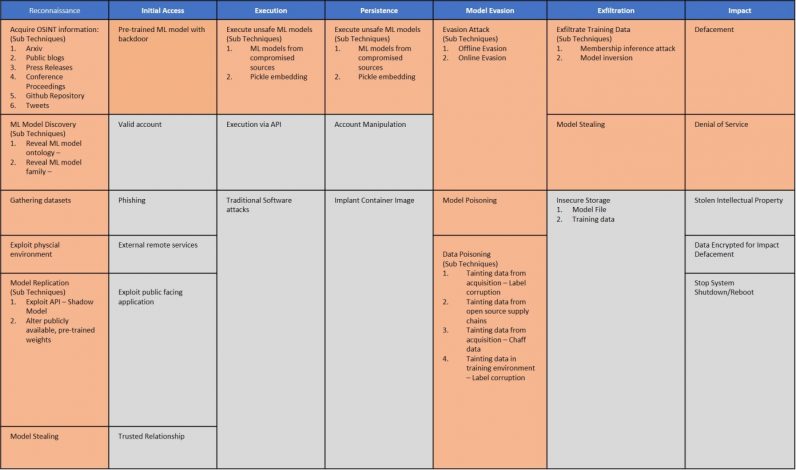
The differences between machine learning models and classic rule-based software require new ways to think about security threats. Earlier this year, several organizations introduced the Adversarial ML Threat Matrix, a framework that helps find weaknesses in machine learning pipelines and patch security holes.
While the Threat Matrix focuses on adversarial attacks, its methods are also applicable to threats such as EvilModels. Until researchers find more robust methods to detect and block malware in deep neural networks, we must establish a chain of trust in machine learning pipelines. Knowing that malware scanners and static analysis tools can’t detect infected models, developers must make sure their models come from trusted sources and the provenance of training data and learned parameters are not compromised. As we continue to learn about the security of deep learning, we must be wary of what’s hidden behind the millions of numbers that get crunched to analyze our photos and recognize our voices.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Get the TNW newsletter
Get the most important tech news in your inbox each week.