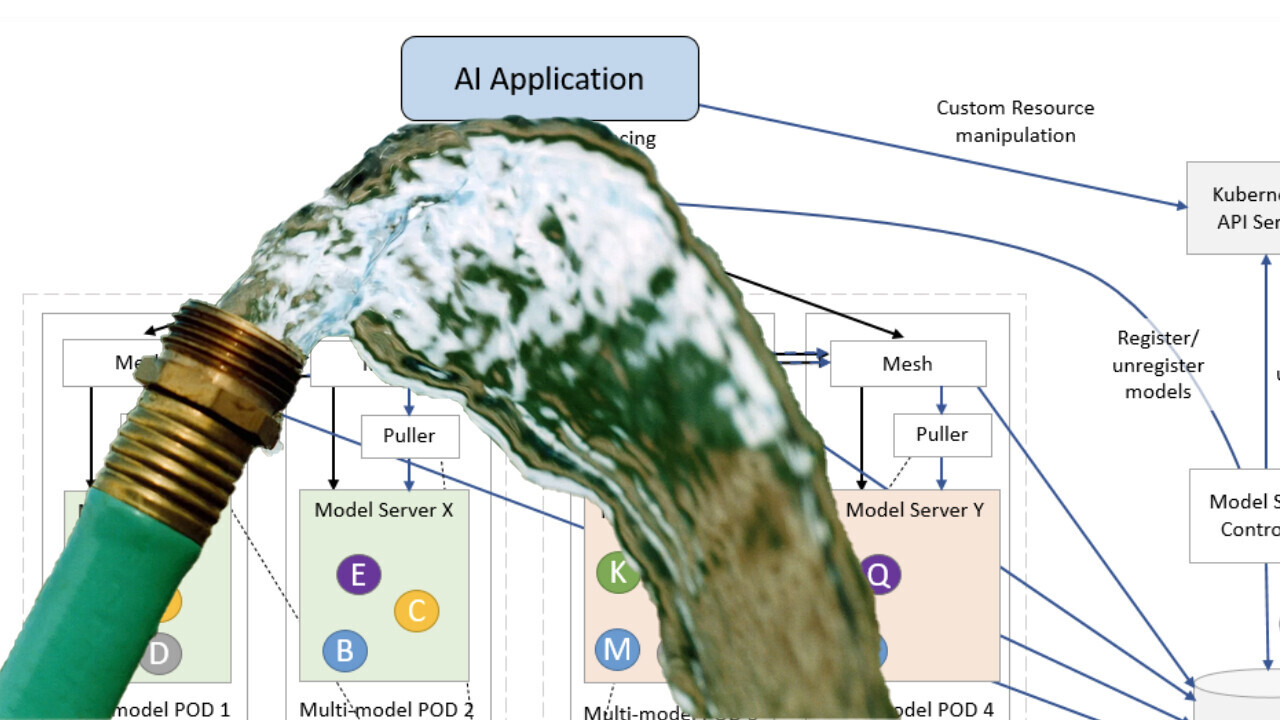
IBM today announced it has committed its ModelMesh inference service to open source. This is a big deal for the MLOps and DevOps community, but the implications for the average end-user are also huge.
Artificial intelligence is a backbone technology that nearly all enterprises rely on. The majority of our coverage here on Neural tends to discuss the challenges involved in training and developing AI models.
But when it comes to deploying AI models so that they can do what they’re supposed to do when they’re supposed to do it, the sheer scale of the problem is astronomical.
Think about it: you log in to your banking account and there’s a discrepancy. You tap the “How can we help?” icon at the bottom of your screen and a chat window opens up.

The <3 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
You enter a query such as “Why isn’t my balance reflecting my most recent transactions?” A chat bot responds with “One moment, I’ll check your account,” and then, like magic, it says “I’ve found the problem” and gives you a detailed response concerning what’s happened.
What you’ve done is sent an inference request to a machine learning model. That model, using a technique called natural language processing (NLP), parses the text in your query and then sifts through all of its training data to determine how best it should respond.
If it does what it’s supposed to in a timely and accurate manner, you’ll probably walk away from the experience with a positive view on the system.
But what if it stalls or doesn’t load the inferences? You end up wasting your time with a chat bot and still need your problem solved.
ModelMesh can help.
Animesh Singh, IBM CTO for Watson AI & ML Open Tech, told Neural:
ModelMesh underpins most of the Watson cloud services, including Watson Assistant, Watson Natural Language Understanding, and Watson Discovery and has been running for several years.
IBM is now contributing the inference platform to the KServe open source community.
Designed for high-scale, high-density, and frequently-changing model use cases, ModelMesh can help developers scale Kubernetes.
ModelMesh, combined with KServe, will also add Trusted AI metrics like explainability, fairness to models deployed in production.
Going back to our banking customer analogy, we know that we’re not the only user our bank’s AI needs to serve inferences to. There could be millions of users querying a single interface simultaneously. And those millions of queries could require service from thousands of different models.
Figuring out how to load all these models in real-time so that they can perform in a manner that suits your customer’s needs is, perhaps, one of the biggest challenges faced by any company’s IT team.
ModelMesh manages both the loading and unloading of models to memory to optimize functionality and minimize redundant power consumption.
Per an IBM press release:
It is designed for high-scale, high-density, and frequently changing model use cases. ModelMesh intelligently loads and unloads AI models to and from memory to strike an intelligent trade-off between responsiveness to users and their computational footprint.
You can learn more about ModelMesh here on IBM’s website.
Get the TNW newsletter
Get the most important tech news in your inbox each week.