
It’s taken a full year, but GitHub is finished building DGit, an all-new distributed storage system that will improve just about everything to do with storing and sharing Git content.
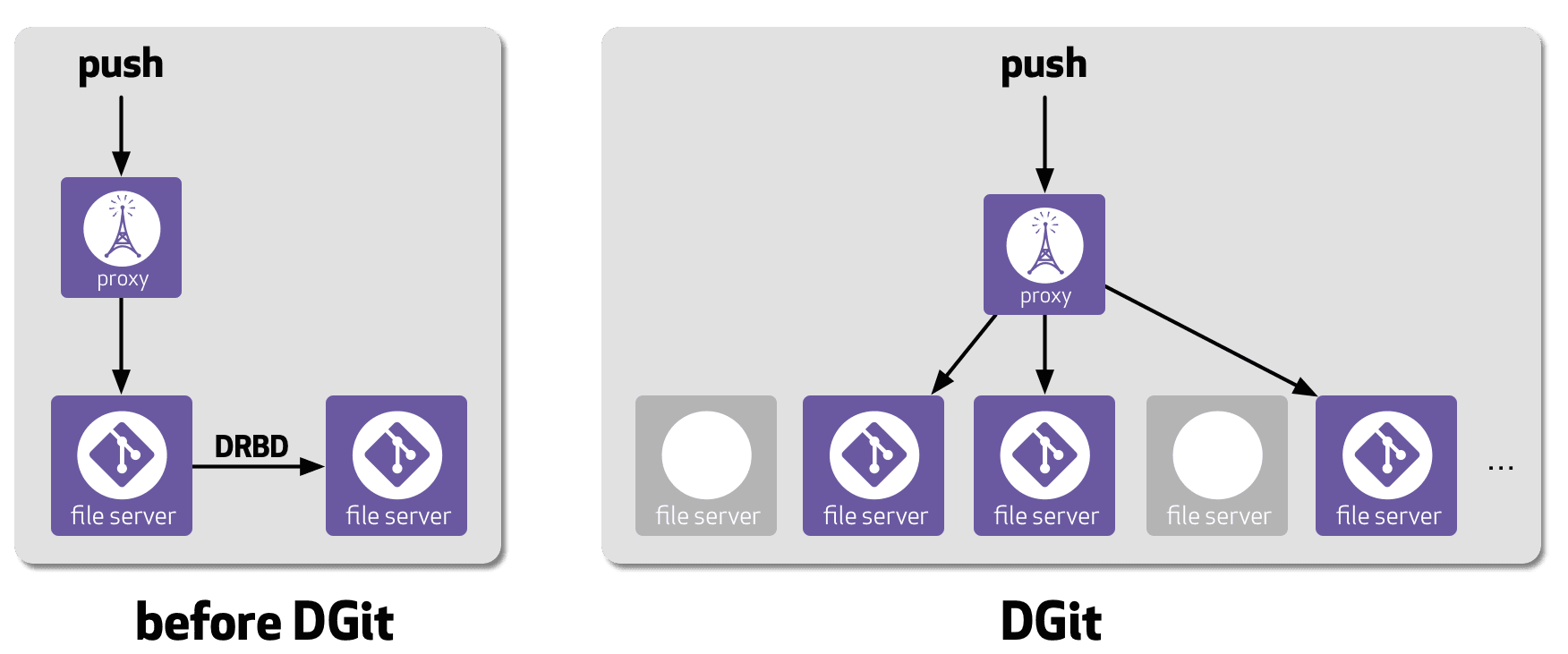
Short for ‘Distributed Git,’ GitHub says DGit “dramatically improves the availability, reliability, and performance” of hosted content. DGit uses the structure of Git — where each copy of a repo contains every file, branch and commit — and makes it available recursively on three different servers.
It’s designed to keep GitHub content available all the time. If one server goes down, there are two others with the same content readily available. If two servers go down (which is highly unlikely), repositories are still readable. Github says fetches, clones and a good chunk of the UI will work just fine.
And that’s good, because we all know how the world crashes when GitHub has an interruption.

The <3 of EU tech
The latest rumblings from the EU tech scene, a story from our wise ol' founder Boris, and some questionable AI art. It's free, every week, in your inbox. Sign up now!
DGit also preforms replication at the application layer, not the disk layer. GitHub encourages us to think of it as “three loosely-coupled Git repositories kept in sync via Git protocols rather than identical disk images full of repositories.” That way, the company says it has greater flexibility to decide where to store repo replicas and which of those replicas to use for read operations.
If a server needs to be taken offline, DGit automatically decides which repos need to be re-replicated on other servers so you don’t miss a beat.
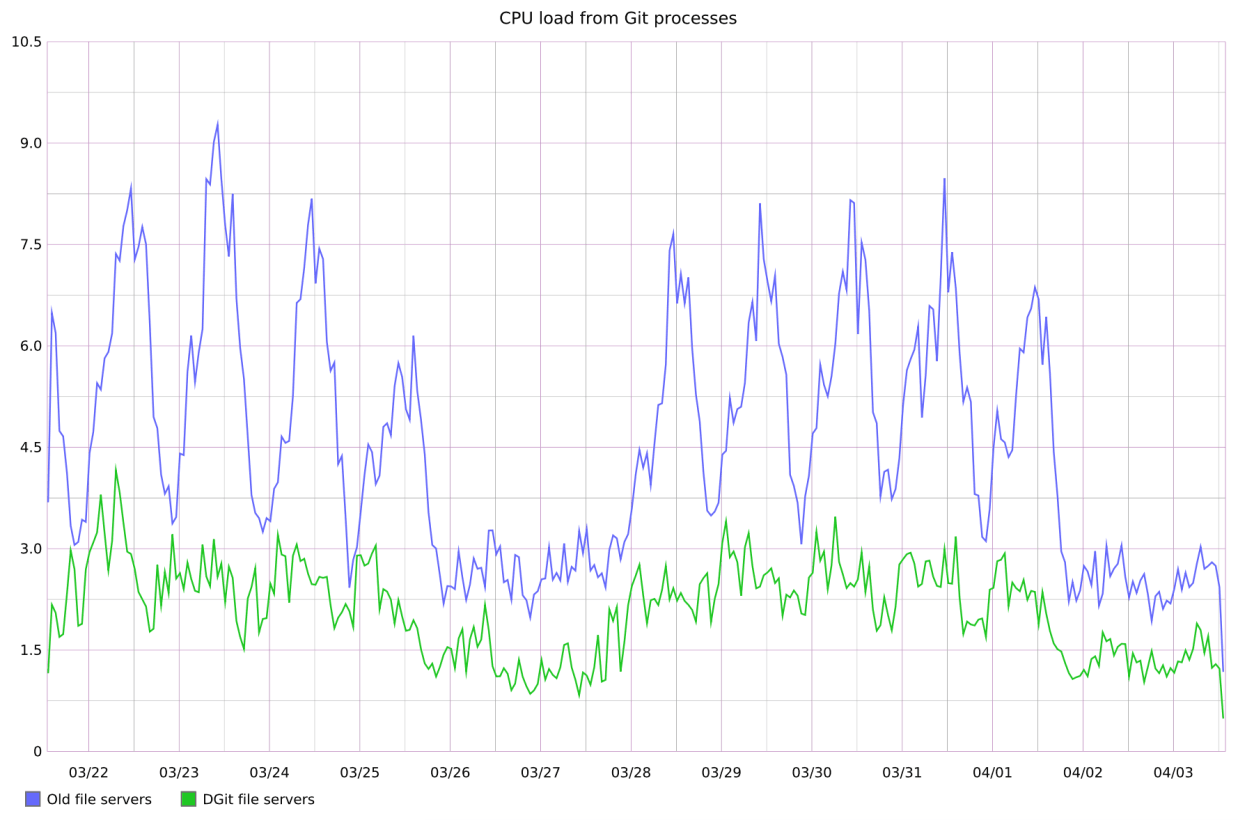
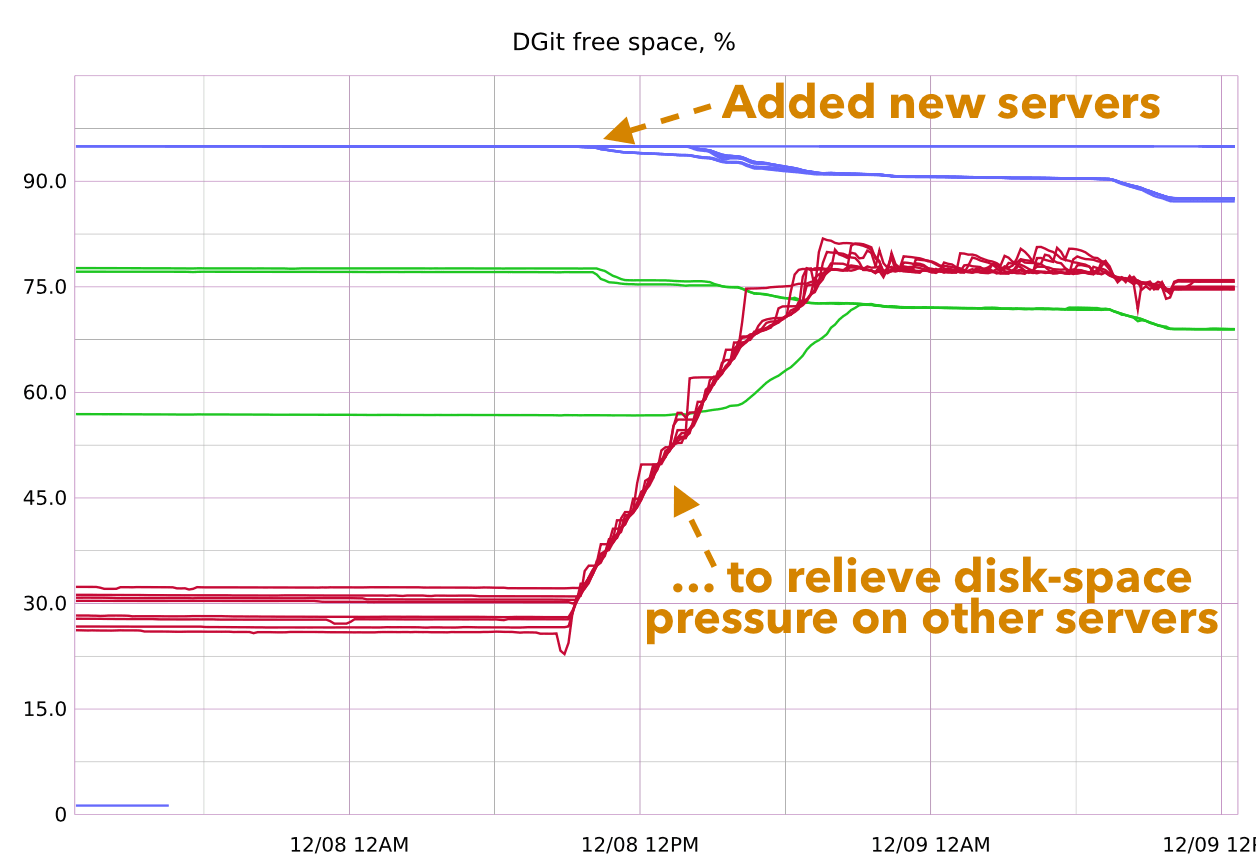

In addition to more up-time, routing around server failures will be less disruptive. Instead of a reboot and re-sync, GitHub can now just stop routing traffic to a server until it recovers. There’s also no need to keep spare, idle servers around.
DGit is a massive shift for GitHub, and it will be rolling it out gradually. Currently, 58% of repositories and 96% of Gists (representing 67% of Git operations) are in DGit. GitHub isn’t offering a timetable for when the change will be complete, but they’ve got most of the work handled, so it shouldn’t take too long.
Get the TNW newsletter
Get the most important tech news in your inbox each week.